- Start on the full version of the new features
- Update DG with design details IMPORTANT!
- Do a release
- Make code RepoSense-compatible
1 Start on the full version of the new features
- Start on implementing the full version of your new feature(s). Aim to finish it in v1.3 (v1.4 can serve as a buffer). As before, you can divide the work into even smaller increments e.g., aim to deliver a v1.2.1 at the end of this week.
- Maintain the defensiveness of the code: Remember to use assertions, exceptions, and logging in your code, as well as other defensive programming measures when appropriate.
Remember to enable assertions in your IDEA run configurations and gradle file. - Continue to do deliberate project management using GitHub issue tracker, milestones, labels, etc. as you did in v1.2.
- We recommend that each PR also updates the relevant parts of documents and tests. That way, your documentation/testing work will not pile up towards the end.
- There is a way to get GitHub to auto-close the relevant issue when a PR is merged (example).
2 Update DG with design details IMPORTANT!
Do a sincere job on this task because this is your only chance to get feedback on the DG before it is graded at v1.4.
- Update the Developer Guide as follows:
- Each member should describe the implementation of at least one enhancement she has added (or planning to add).
Expected length: 1+ page per person - The description can contain things such as,
- How the feature is implemented (or is going to be implemented).
- Why it is implemented that way.
- Alternatives considered.
- Diagramming tools: AB3 uses PlantUML (see instructions) for diagrams. but you may use any other tool (e.g., PowerPoint). If you do, choose a tool that allows incremental updates to diagrams (reason: because diagrams need to be updated multiple times as the product evolves). For example, if you use PowerPoint to draw diagrams, also commit the source PowerPoint files so that they can be reused when updating diagrams in future.
- Each member should describe the implementation of at least one enhancement she has added (or planning to add).
DG Tips
- Aim to showcase your documentation skills. The stated objective of the DG is to explain the implementation to a future developer, but a secondary objective is to show evidence that you can document deeply-technical content using prose, examples, diagrams, code snippets, etc. appropriately. To that end, you may also describe features that you plan to implement in the future, even beyond v1.4 (hypothetically).
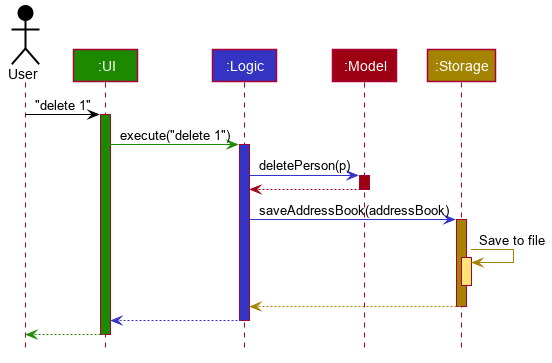
For an example, see the description of the undo/redo feature implementation in the AddressBook-Level3 developer guide. - Use multiple UML diagram types. Following from the point above, try to include UML diagrams of multiple types to showcase your ability to use different UML diagrams.
- Keep diagrams simple. The aim is to make diagrams comprehensible, not necessarily comprehensive. Ways to simplify diagrams:
- Omit less important details. Examples:
- a class diagram can omit minor utility classes, private/unimportant members; some less-important associations can be shown as attributes instead.
- a sequence diagram can omit less important interactions, self-calls.
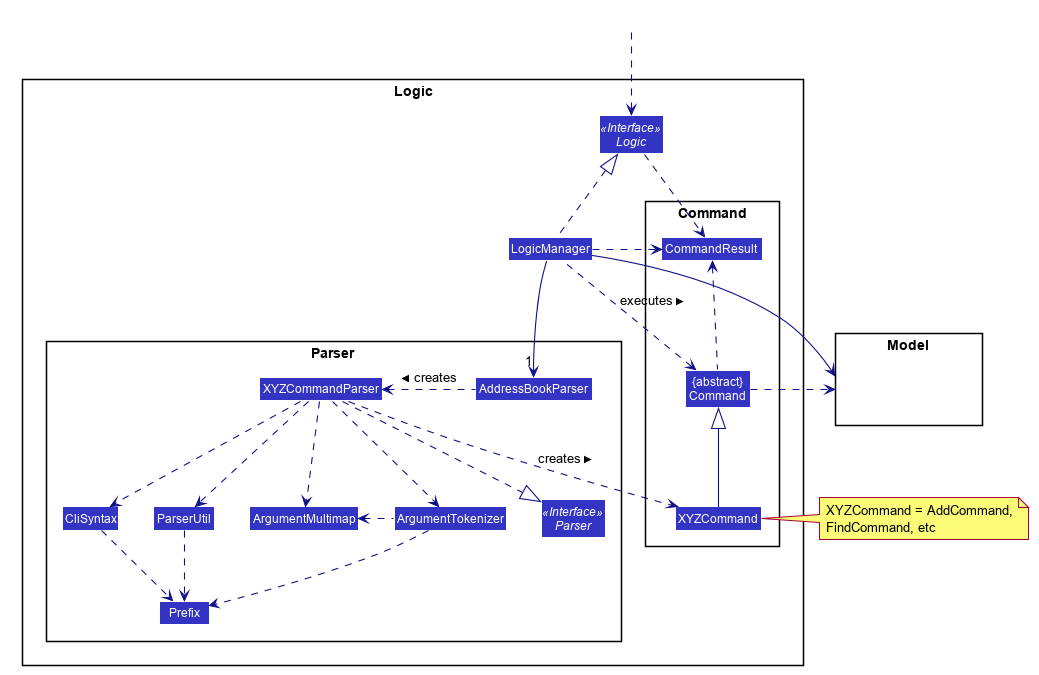
- Omit repetitive details e.g., a class diagram can show only a few representative ones in place of many similar classes (note how the
AB3 Logic class diagram shows concrete*Commandclasses). - Limit the scope of a diagram. Decide the purpose of the diagram (i.e., what does it help to explain?) and omit details not related to it. In particular, avoid showing lower-level details of multiple components in the same diagram unless strictly necessary e.g., note how the
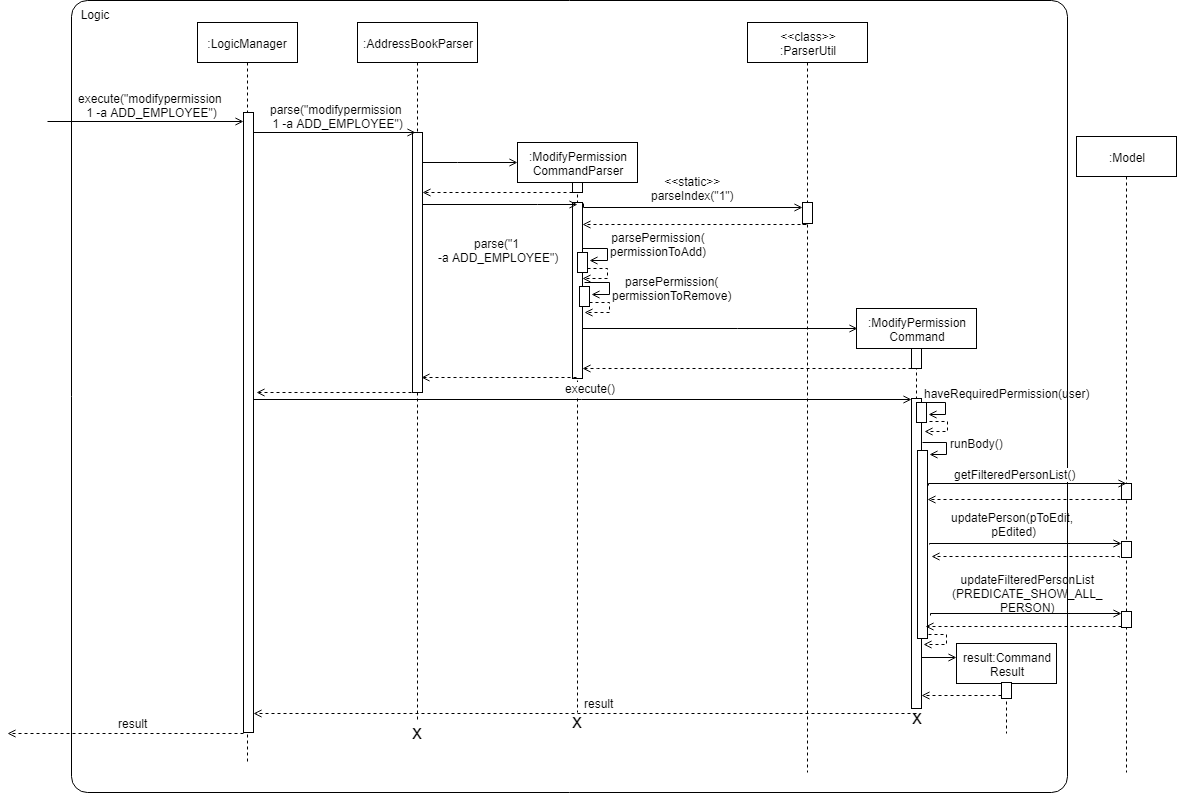
this sequence diagram shows only the detailed interactions within the Logic component i.e., does not show detailed interactions within the model component. - Break diagrams into smaller fragments when possible.
- If a component has a lot of classes, consider further dividing into sub-components (e.g., a Parser sub-component inside the Logic component). After that, sub-components can be shown as black-boxes in the main diagram and their details can be shown as separate diagrams.
- You can use
refframes to break sequence diagrams to multiple diagrams. Similarly,rakes can be used to divide activity diagrams.
- Stay at the highest level of abstraction possible e.g., note how
this sequence diagram shows only the interactions between architectural components, abstracting away the interactions that happen inside each component. - For some more examples, see
here .
- Omit less important details. Examples:
- Integrate diagrams into the description. Place the diagram close to where it is being described.
- Use code snippets sparingly. The more you use code snippets in the DG, and longer the code snippet, the higher the risk of it getting outdated quickly. Instead, use code snippets only when necessary and cite only the strictly relevant parts only.
- Resize diagrams so that the text size in the diagram matches the the text size of the main text of the diagram. See
example .
These class diagrams seem to have lot of member details, which can get outdated pretty quickly:
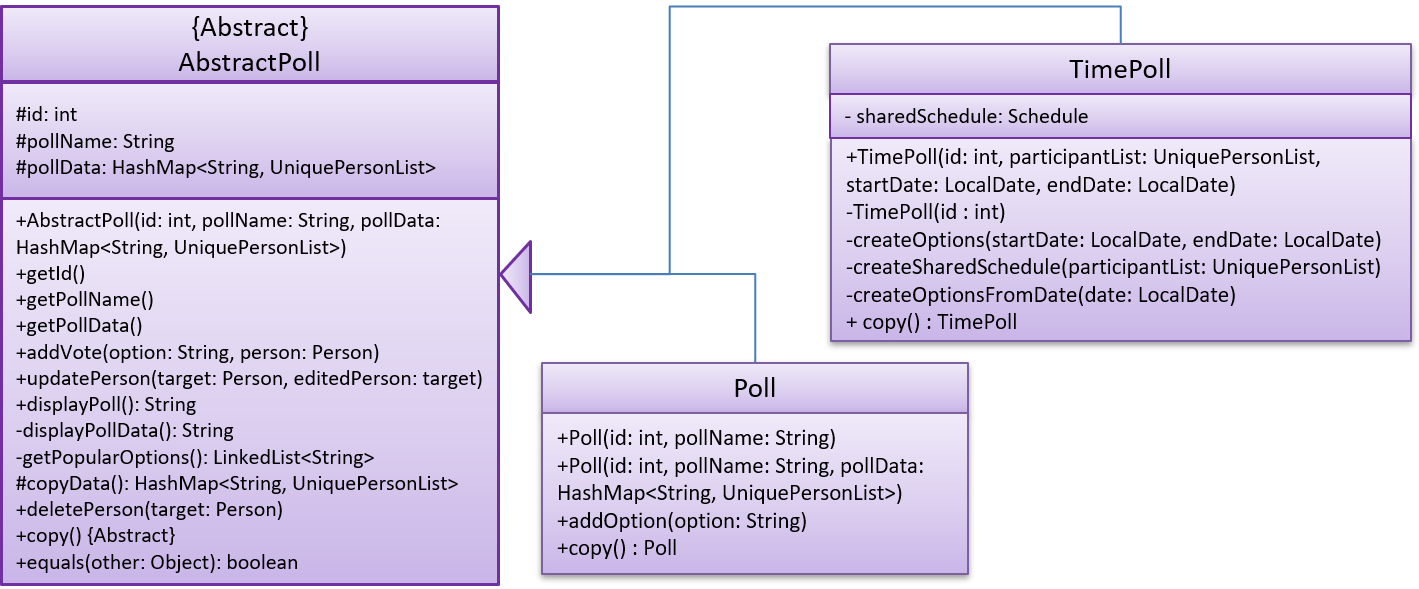
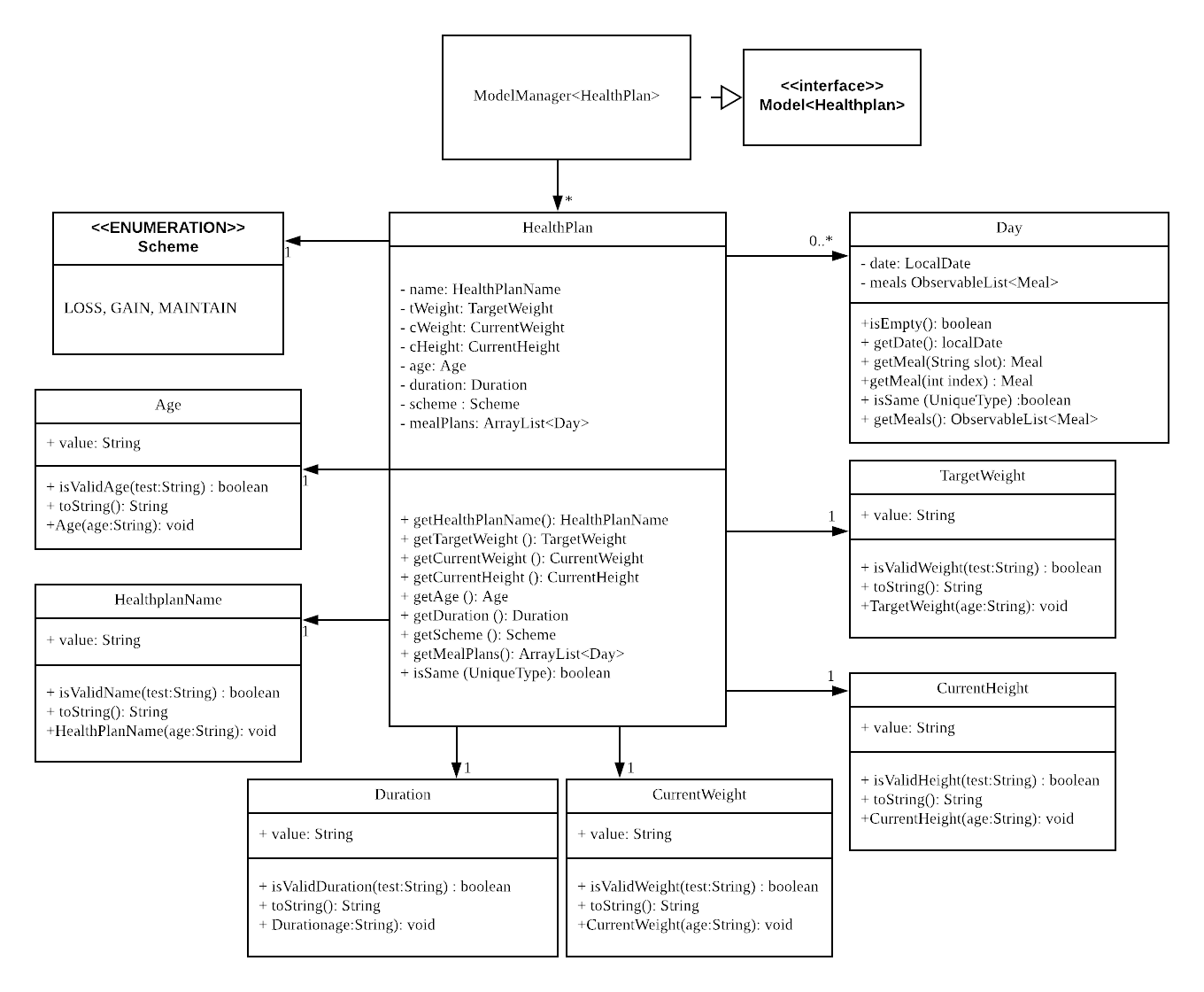
This class diagram seems to have too many classes:
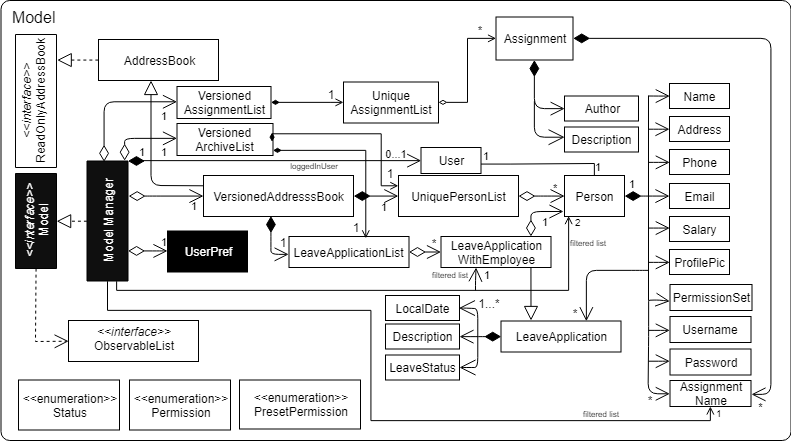
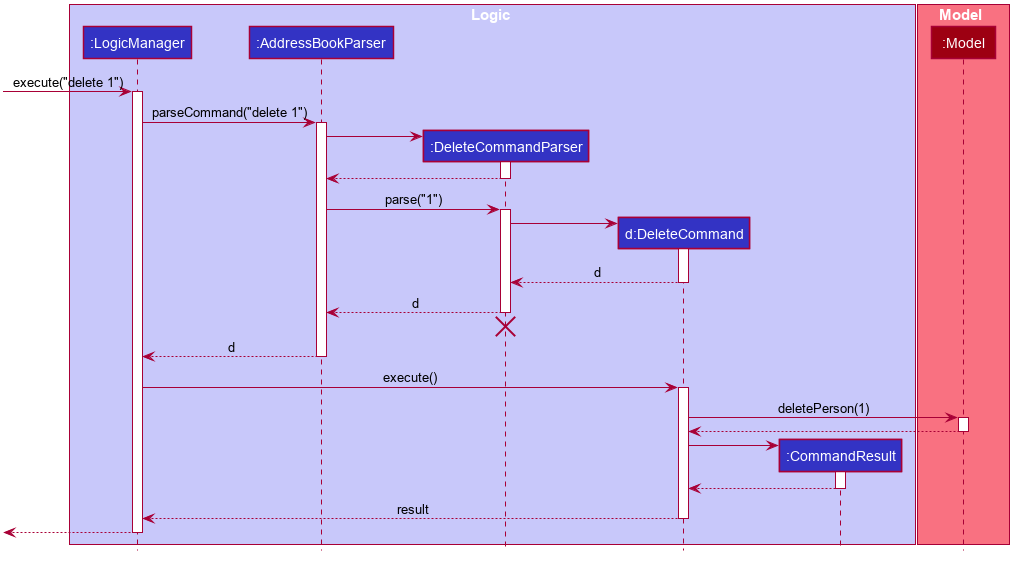
These sequence diagrams are bordering on 'too complicated':
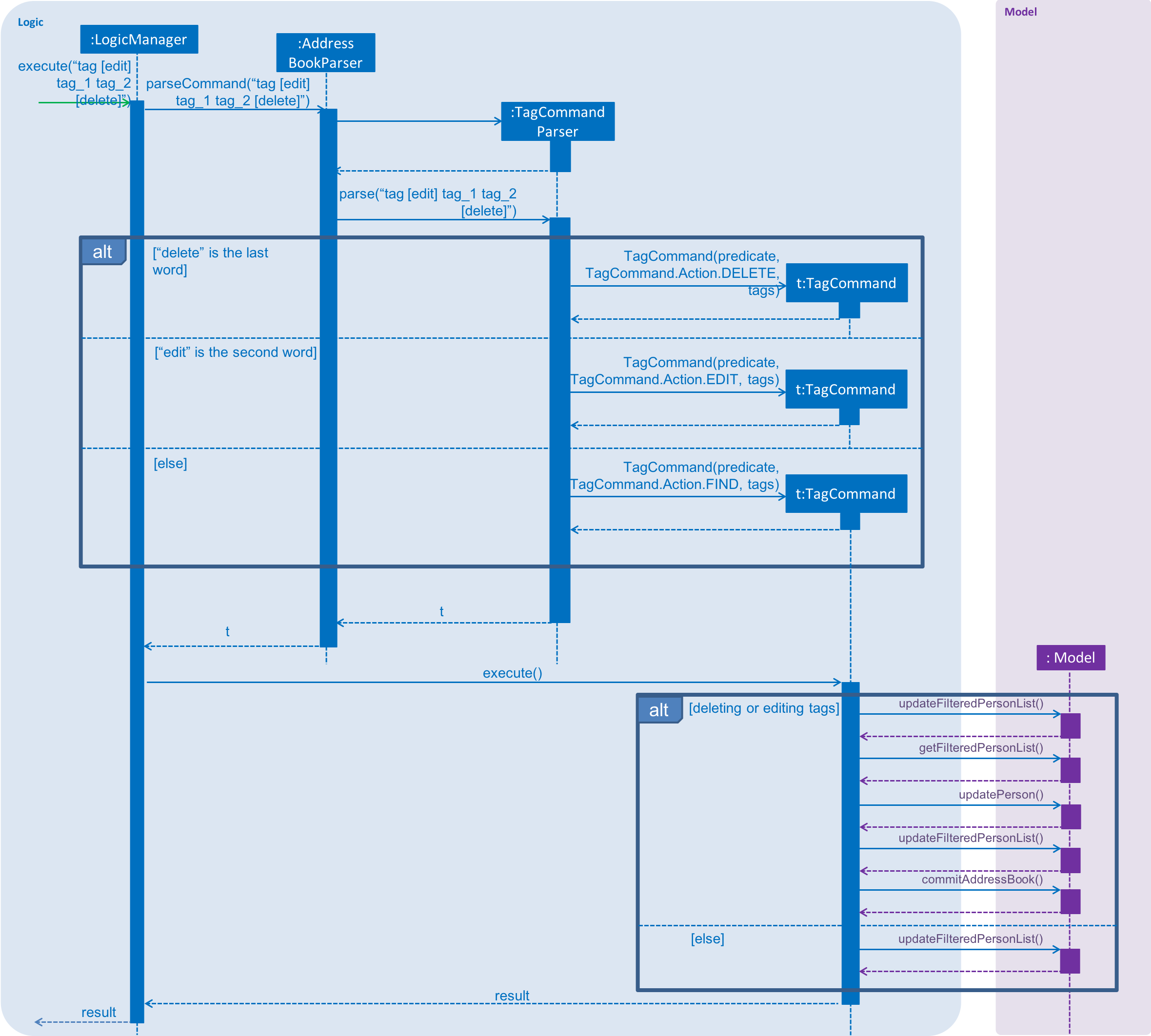
In this negative example, the text size in the diagram is much bigger than the text size used by the document:

It will look more 'polished' if the two text sizes match.
3 Do a release
-
Do a
proper product release as described in the Developer Guide. You can name it something likev1.2.1. Ensure that the jar file works as expected by doing some manual testing. Reason: You are required to do a proper product release for v1.3. Doing a trial at this point will help you iron out any problems in advance. It may take additional effort to get the jar working especially if you use third party libraries or additional assets such as images.
4 Make code RepoSense-compatible
-
Ensure your code is
RepoSense-compatible and the code it attributes to you is indeed the code written by you, as explained below:- Go to the tp Code Dashboard. Click on the
</>icon against your name and verify that the lines attributed to you (i.e., lines marked as green) reflects your code contribution correctly. This is important because some aspects of your project grade (e.g., code quality) will be graded based on those lines.
- More info on how to make the code RepoSense compatible:
- Go to the tp Code Dashboard. Click on the
Relevant: [
Tool Used: RepoSense (for Analyzing Code Authorship)
We will be using a tool called RepoSense to make it easier for you to see (and learn from) code written by others, and to help us see who wrote which part of the code.
Viewing the current status of code authorship data:
- The report generated by the tool will be made available at tP Code Dashboard at some point in the semester. The feature that is most relevant to you is the Code Panel (shown on the right side of the screenshot above). It shows the code attributed to a given author.
- Click on your name to load the code attributed to you (based on Git blame/log data) onto the code panel on the right.
- If the code shown roughly matches the code you wrote, all is fine and there is nothing for you to do.
2. If the code does not match the actual authorship:
-
Here are the possible reasons for the code shown not to match the code you wrote:
- the git username in some of your commits does not match your GitHub username.
- the actual authorship does not match the authorship determined by git blame/log e.g., another student touched your code after you wrote it, and Git log attributed the code to that student instead
-
In those cases, you can provide more information to RepoSense to rectify the situation, in the following way:
For simple cases such as the following, you can create a PR to update our config files here. The meaning of the config files are given in the RepoSense user guide.
- missing some commits due to using multiple git
user.names - some commits/files need to be omitted from the analysis
For more complicated needs, follow the instructions below this box. If you are not sure which option to use, please post in the forum to ask.
- Install RepoSense (see the Getting Started section of the RepoSense User Guide)
- Use the two methods described in the RepoSense User Guide section Configuring a Repo to Provide Additional Data to RepoSense to provide additional data to the authorship analysis to make it more accurate.
- If you add a
config.jsonfile to your repo (as specified by one of the two methods),- Please use the exact partial name from here as the display name.
e.g.,"displayName": "ABDUL ... JAVID", - If your commits have multiple author names, specify all of them
e.g.,"authorNames": ["theMyth", "theLegend", "The Gary"] - Update the line
config.jsonin the.gitignorefile of your repo as/config.jsonso that it ignores theconfig.jsonproduced by the app but not the_reposense/config.json.
- Please use the exact partial name from here as the display name.
- If you add
@@authorannotations, please follow the guidelines below:
Adding @@author tags indicate authorship
-
Mark your code with a
//@@author {yourGithubUsername}. Note the double@.
The//@@authortag should indicates the beginning of the code you wrote. The code up to the next//@@authortag or the end of the file (whichever comes first) will be considered as was written by that author. Here is a sample code file://@@author johndoe method 1 ... method 2 ... //@@author sarahkhoo method 3 ... //@@author johndoe method 4 ... -
If you don't know who wrote the code segment below yours, you may put an empty
//@@author(i.e. no GitHub username) to indicate the end of the code segment you wrote. The author of code below yours can add the GitHub username to the empty tag later. Here is a sample code with an emptyauthortag:method 0 ... //@@author johndoe method 1 ... method 2 ... //@@author method 3 ... method 4 ... -
The author tag syntax varies based on file type e.g. for java, css, fxml. Use the corresponding comment syntax for non-Java files.
Here is an example code from an xml/fxml file.<!-- @@author sereneWong --> <textbox> <label>...</label> <input>...</input> </textbox> ... -
Do not put the
//@@authorinside java header comments.
👎/** * Returns true if ... * @@author johndoe */👍
//@@author johndoe /** * Returns true if ... */
What to and what not to annotate
-
Annotate both functional and test code There is no need to annotate documentation files.
-
Annotate only significant size code blocks that can be reviewed on its own e.g., a class, a sequence of methods, a method.
Claiming credit for code blocks smaller than a method is discouraged but allowed. If you do, do it sparingly and only claim meaningful blocks of code such as a block of statements, a loop, or an if-else statement.- If an enhancement required you to do tiny changes in many places, there is no need to annotate all those tiny changes; you can describe those changes in the Project Portfolio page instead.
- If a code block was touched by more than one person, either let the person who wrote most of it (e.g. more than 80%) take credit for the entire block, or leave it as 'unclaimed' (i.e., no author tags).
- Related to the above point, if you claim a code block as your own, more than 80% of the code in that block should have been written by yourself. For example, no more than 20% of it can be code you reused from somewhere.
- GitHub has a blame feature and a history feature that can help you determine who wrote a piece of code.
-
Do not try to boost the quantity of your contribution using unethical means such as duplicating the same code in multiple places. In particular, do not copy-paste test cases to create redundant tests. Even repetitive code blocks within test methods should be extracted out as utility methods to reduce code duplication. Individual members are responsible for making sure code attributed to them are correct. If you notice a team member claiming credit for code that he/she did not write or use other questionable tactics, you can email us (after the final submission) to let us know.
-
If you wrote a significant amount of code that was not used in the final product,
- Create a folder called
{project root}/unused - Move unused files (or copies of files containing unused code) to that folder
- use
//@@author {yourGithubUsername}-unusedto mark unused code in those files (note the suffixunused) e.g.
//@@author johndoe-unused method 1 ... method 2 ...Please put a comment in the code to explain why it was not used.
- Create a folder called
-
If you reused code from elsewhere, mark such code as
//@@author {yourGithubUsername}-reused(note the suffixreused) e.g.//@@author johndoe-reused method 1 ... method 2 ... -
You can use empty
@@authortags to mark code as not yours when RepoSense attribute the to you incorrectly.-
Code generated by the IDE/framework, should not be annotated as your own.
-
Code you modified in minor ways e.g. adding a parameter. These should not be claimed as yours but you can mention these additional contributions in the Project Portfolio page if you want to claim credit for them.
-
- After you are satisfied with the new results (i.e., results produced by running RepoSense locally), push the
config.jsonfile you added and/or the annotated code to your repo. We'll use that information the next time we run RepoSense (we run it at least once a week). - If you choose to annotate code, minimize annotating code chunks smaller than a method. We do not grade code snippets too small to be read meaningfully.
- If you encounter any problem when doing the above or if you have questions, please post in the forum.
We recommend you ensure your code is RepoSense-compatible by v1.3